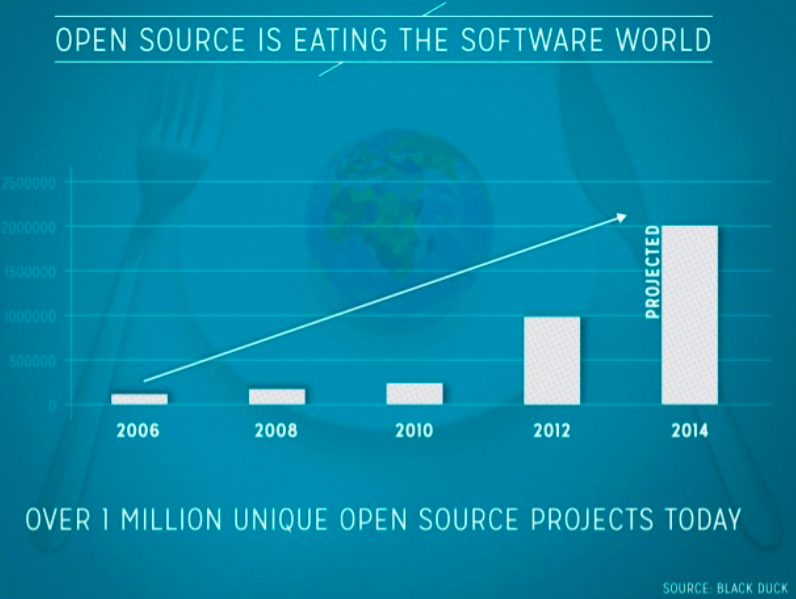
My researchers keep track of useful Web sites. As Bing and Google shift from “search” to other information interests, having a library card catalog of Web information resources becomes more important. I want to highlight five “search” services that may be useful to a person conducting business intelligence or basic research.
Infomine http://infomine.ucr.edu/
This site provides basic and advanced search for “scholarly Internet collections.” The free service provides a hotlink to subject categories. A partial listing of the categories includes:
- Biology, agriculture, and medical information
- Business and economics information
- Electronic journals
- Physical science, engineering, computer science and mathematics.
The service is provided by the Regents of the University of California. The public facing system was developed by information professionals of the Riverside University of California Riverside.
A query for “online video” returns hits for the Pew Internet and American Life Project. The same query run via the advanced search option provides an interface with a number of helpful options:
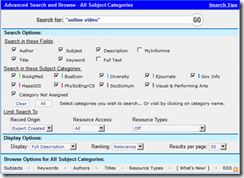
Link: http://infomine.ucr.edu/cgi-
The results were narrowed from 1,600 hits to 341. This resource is more useful for academic queries. I have found it useful for more general queries about specific technical issues such as “thorium reactor”.
The key differentiator with Infomine is that a subject matter expert selected the sites in the system’s index. I am not a fan of uncontrolled comments. Infomine allows a researcher to add information to a specific result.
Directory of Open Access Journals http://www.doaj.org/
Editorial controls on academic journals vary significantly from title to title and publisher to publisher. I have encountered publishers who knowingly leave articles containing bogus information in their commercial indexes. I have brushed against publishers who look “academic” but are really fronts for conference programs. If you don’t have access to commercial databases or don’t know what database to use when searching your local library’s online servicers, navigate to DOAJ.
The system indexes about 10,000 open access journals. Content can vary because some open access journals do not make their articles available without a fee. You can access about 5600 journals and view the full text without paying a fee. The service offers an advanced search function. The interface for my query “Inconel” looks like this:
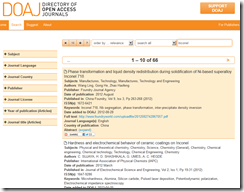
The articles were on point. The top hit referenced “phase transformation”, one of the key characteristics of this specialized steel. When looking for technical information, I encourage my researchers to run the query using synonyms across multiple systems. A good rule of thumb is that competitive services have an overlap of 70 to 80 percent. In many cases, the overlap is much lower. Running the same query across multiple indexes usually provides additional insight into useful sources of information.
NSDL (National Science Digital Library) http://nsdl.org/search/
NSDL is funded by the National Science Foundation. The system “provides access to high quality online educational resources” for teaching and learning. The system points to resources. For a person investigating or researching a topic, NSDL can pinpoint people, institutions, and content germane to a scientific query. I ran a query for “phase diagram.” The system returned educational materials as the top ranked hit. However, the fourth hit pointed to a technical paper, provided a hot link to the author, and permitted a free download of the PDF of the research report.
If you are looking for other US government technical information, be sure to include Science.gov. Unlike USA.gov, Science.gov taps the Deep Web Technology federated search engine. Another must use site is the www.nist.gov resource. Searching US government Web sites directly often returns results not in the USA.gov search index.
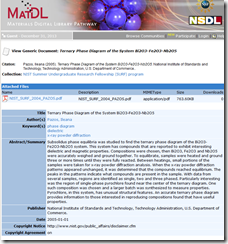
The NSDL system displayed content from the Material Digital Library Pathway. Link: http://matdl.org/repository/
Science.gov http://www.science.gov/
Science.gov searches over 60 databases and over 2200 selected Web sites from 15 Federal agencies. The system provides access to information on about 200 million pages of content.
Science.gov 5.0 provides the ultimate science search through a variety of features and abilities, including:
- Accessing over 55 databases and 200 million pages of science information via one query
- Clustering of results by subtopics, authors, or dates to help you target your search
- Wikipedia results related to your search terms
- Eureka News results related to your search terms
- Mark & send option for emailing results to friends and colleagues
- Download capabilities in RIS
- Enhanced information related to your real-time search
- Aggregated Science News Feed, also available on Twitter
- Updated Alerts service
- Image Search
My test query was “thorium reactor.” The information was on point. The screenshot of the basic query’s search results appear below:
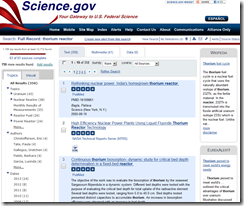
There are quite a few bells and whistle available. I typically focus on the text results, ignoring the related topics and sidebar “snippets.” An advanced search function is not available. There is, however, a “refine search” function that allows the initial search result set to be narrowed. The system displays the first results that come back from the Deep Web federating engine. You can view only these or instruct the system to integrate the full set of hits into the results list. I strongly recommend getting the full results list even though latency is added to the system.
Unlike USA.gov, Science.gov has focused on search. USA.gov is an old-style portal, almost like a Yahoo for the US government’s publicly accessible information. Science.gov is more useful to me, but you may find USA.gov helpful in your research.
I want to highlight other search resources in 2014. I find Google useful, but it is becoming more and more necessary to run queries across different systems. You can find more online research tips and tricks at DeeperQI.com, edited by librarians for business researcher and competitive intelligence professionals.