In the first part of this article, we told you about targeted cyber attacks and how cyber criminals penetrate corporate networks, attacking the computers of employees who use their desktops for social networking and other cyber-skiving.
Along with targeted cyber attacks there are other threats. Intentionally or by chance, employees may be guilty of disclosing confidential data or breaking copyright laws, which might result in law suits against the company.
We will tell you about some incidents related to the storage and transfer of corporate documents via a personal mailbox or a cloud service and the use of software for P2P file sharing. We will explain what technologies and security policies allow system administrators and IT security specialists to prevent such incidents.
Reputation loss
Your company’s reputation is worth protecting - and not only from cyber criminals. Employees who send professional correspondence to their personal mailboxes, download illegal content, or use pirated software on corporate computers never think they might damage their company’s reputation.
Confidential information disclosure
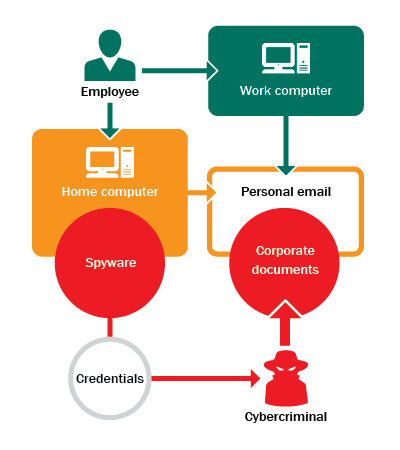
One company faced an accident in which extremely confidential information was disclosed. Data security specialists started the investigation by checking the leaked documents and were surprised to learn that the metadata contained important information - the company’s name, computer’s name, where the document was stored for the last time, authors’ names, e-mail addresses, telephone numbers, and more. Criminals usually delete this data to hide the source of the leak. During the investigation, the experts found that the copies of disclosed documents were stored on the computers of five employees. None of them admitted to handing the documents over to a third party; moreover, having learnt about the accident at the interview with the security, all of them were genuinely surprised. After analyzing the corporate proxy-server logs, it was revealed that one of those five employees had uploaded copies of the disclosed files to a mail service.
At the second interview, this employee confessed that he had used his personal mailbox a few times to store corporate documents. It was convenient: if he had no time to finish or read a document, he sent it to his personal mail and finished it at home. Any employee could gain remote access to his corporate mailbox on request, but the employee hadn’t set up any extra protections. He didn’t anticipate any problems with using his personal mailbox for work.
Having gained access to his personal mailbox, data security specialists checked the list of IP addresses used to connect to the e-mail. Along with the employee’s home and corporate IP addresses, a lot of other addresses of proxy-servers from different countries surfaced.
While investigating the employee’s computer security, specialists discovered spyware that logged all the account data for different systems - sites, social networks, mailboxes, and online banking services. Having used the malware to gain access to the employee’s mailbox, the criminal found a lot of corporate documents stored there.
Though the guilty employee was fired; the reputational damage to the company lingers on.
Breach of copyright
It’s widely known that pirate content download is a violation of copyright law. However, few people remember that when you use the Internet from your corporate network, you use the IP address of your company. This means that if a violation is discovered, it is the company who will be liable.
A small company suffered an unpleasant incident. At certain times, there was a sharp drop in Internet connection speeds. Network traffic statistics showed one computer using 80% of the network capacity, with in-coming and out-going connections going off the scale. The sysadmin assumed that the computer was used to share files on a P2P network.
It turned out that one employee had brought his personal laptop and connected it to the corporate network. A BitTorrent client installed on the laptop was set to run automatically when the system started. The employee had forgotten all about it and the program running on his laptop caused trouble with the Internet connection.
Three months later, local law enforcement authorities came to the office with a search warrant and took many hard drives and documents, because they suspected that the company had used pirated software, in breach of copyright rules. In the end, the company was fined and, since then, stronger restrictions against pirate software have been introduced in the security policy. Now, employees face serious sanctions for a first offense, and lose their jobs if there is any repeat. In addition to those punishments, illegal content (hacked software, video, music, e-books, etc.) is forbidden whether it is downloaded to a corporate computer from the Internet, or if it is brought from home.
Solution
We described just two cases in which the violation of corporate policies by employees led to serious incidents. In everyday life, there are many more scenarios like this. Fortunately, there are also some simple methods, which, together with security policies, can help to prevent the majority of these incidents.
Network Traffic Control
In the incident described above - corporate documents leaked and unlicensed content loaded via P2P - the corporate network served as a channel to send and receive data. Firewall, IPS, HIPS, and other technologies allow system administrators and IT security specialists to limit or block:
- Access to public services and their servers - mail services, cloud storages, sites with forbidden content, etc.
- Use of ports and protocols for P2P sharing
- Sending corporate data outside the corporate network
It’s worth remembering that no single control of network traffic can provide the highest level of corporate network security. In order to bypass security policies, employees can use traffic encryption methods, connect to the copies (mirrors) of blocked online services, or use proxy servers and anonymizers. Moreover, many applications can use other application ports and embed their traffic into various protocols, which cannot be forbidden. In spite of these obstacles, network traffic control is important and necessary, but it needs to be combined with application control and file encryption.
Application control
Using application control, a system administrator or data security specialist can not only forbid any unwanted software, but also track what applications employees use, as well as when and where they use them. It’s almost impossible to prohibit all pirated software, as a lot of varieties of an application may be created and they may be almost identical. So, the most effective approach is to use application control in default deny mode to ensure that all employees use only authorized software.
File encryption
It’s often impossible to track how employees use cloud services and personal mailboxes to store corporate data, which may include confidential information. Many mail services and cloud storages encrypt files transmitted by a user but cannot guarantee protection against intruders - a stolen login and password will give access to the data.
To prevent this type of theft, many online services attach cell phone numbers to their accounts. Along with the account data, a criminal will need to intercept a one-off confirmation code, sent to a mobile device during authorization. Note that this protection is safe only if the mobile device has no malware that will let the criminal see the code.
Fortunately, there is a safer way to provide security for corporate documents transmitted beyond the corporate network - file encryption technology. Even if intruders get access to a mailbox or cloud storage where an employee stores corporate papers, they won’t be unable to access the content of these documents, since they have been encrypted before their transmission to an external server.
Security policies
Network traffic control, application control, and data encryption are important security measures that can detect and automatically prevent data leaks as well as restrict the use of unwanted software on the corporate network. It’s still necessary, however, to implement security policies and increase employee awareness, since many users do not realize their actions may threaten their company.
In case of repeated violations, security policies should lead to administrative sanctions towards the offender, including dismissal.
Security policies should also stipulate the actions that should be taken if a former employee has access to confidential information or critical infrastructure systems.
Conclusion
Incidents like confidential data leaks or unlicensed content loaded from a corporate IP address may cause significant damage to a company’s reputation.
To prevent this damage, companies should limit or completely block employee access to online resources that may be a threat to a company, and also limit or block the use of those ports, data transmission protocols, and applications that are not required for work. File encryption technologies should be used in order to ensure the confidentiality and integrity of corporate documents.
IT security experts should keep in mind that, along with incident detection and prevention, they should pay attention to administrative protection measures. Users should be aware of what is allowed and prohibited by a security policy and the consequences of any violation.
