
The number of open source frameworks that are available today is continuously growing at an enormous pace with over 1 million unique open source projects today, as indicated in a recent survey by Black Duck.
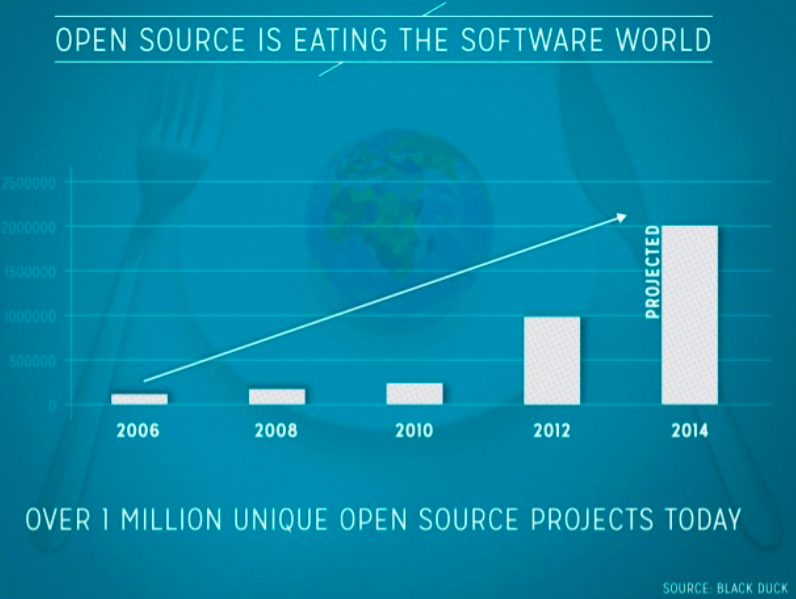
The availability of these frameworks has changed the way we build products and structure our IT infrastructure. Products are often built through integration of different open source frameworks rather than developing the entire stack.
The speed of innovation is also an area that has changed as a result of this open source movement. Where, previously, innovation was mostly driven by the speed of development of new features, in the open source world, innovation is greatly determined by how fast we can integrate and take advantage of new open source frameworks.
Having said that, the process of trying out new open source frameworks can still be fairly tedious, especially if there isn’t a well-funded company behind the project. Let me explain why.
Open Source Framework Integration Continuum
The integration of a new open source framework often goes through an evolution cycle that I refer to as the integration continuum.
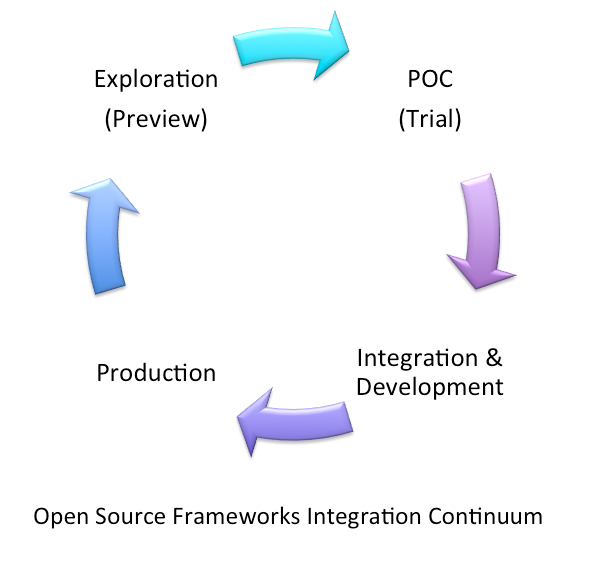
A typical integration process often involves initial exploration where we continuously explore new frameworks, sometimes without any specific need in mind. At this stage, we want to be able to get a feel of the framework, but don’t necessarily have the time to take a deep dive into the technology or deal with complex configurations. Once we find a framework that we like and see a potential use for it, we start to look closer and run a full POC.
In this case, we already have a better idea of what the product does and how it can fit in our system, but we want to validate our assumptions. Once we are done with the POC and found what were looking for, we start the integration and development stage with our product.
This stage is where we are often interested in getting our hands on the API and the product features, and need a simple environment that will allow us to quickly test the integration of that API with our product. As we get closer to production, we get more interested in the operational aspects and need to deal with building the cluster for high availability, adding more monitoring capabilities and integrating it with our existing operational environment.
Each of those steps often involves downloading the framework, setting up the environment and tuning it to fit the need of the specific stage (i.e. trial, POC, dev, production). For obvious reasons, the requirements for each of those stages are fairly different, so we typically end up with a different setup process with various tools in each step, leading to a process in which we are continuously ripping and replacing the setup from the previous step as we move from one stage to the next.
The Friction Multiplier Effect
The friction that I was referring to above refers to a process for a single framework. In reality, however, during the exploration and POC stages, we evaluate more than one framework in order to choose the one that best fits our needs.
In addition, we often integrate with more than one product or framework at a time. So in reality, the overhead that I was referring to is multiplied by the number of frameworks that we are evaluating and using. The overhead in the initial stages of exploration and POC often ends in complete waste as we typically choose one framework out of several, meaning we spent a lot of time setting up frameworks that we are never going to use.
What about Amazon, GAE or Azure Offerings?
These clouds limit their services to a particular set of pre-canned frameworks and the infrastructure and tools that most clouds offer are not open source. This means that you will not be able to use the same services under your own environment. It also introduces a higher degree of locking.
Flexibility is critical as the industry moves toward more advanced development and production scenarios. This could be a huge stop gap. If you get stuck with the out of the box offering, you have no way to escape, with your only way out to build the entire environment yourself, using other sets of tools to build the entire environment completely from scratch.
A New Proposition
Looking at existing alternatives, there is a need for a hassle-free preview model that enables a user to seamlessly take a demo into production with the flexibility to be fully customizable and adaptable. With GigaSpaces’ Cloudify Application Catalog, we believe that the game is changing. This new service, built on HP’s OpenStack-based Public Cloud, makes the experience of deploying new open source services and applications on OpenStack simpler than on other clouds. By taking an open source approach, it’s guaranteed not to hit a stop-gap as we advance through the process and avoid the risk of a complete re-write or lock-in. At the same time we allow hassle free one-click experience by providing an “as-a-service” offering for deploying any of our open source frameworks of choice. By the fact that we use the same underlying infrastructure and set of tools through all the cycles, users can take their experience and investment from one stage to the other and thus avoid a complete re-write.
Final Words
In today’s world, innovation is key to allowing organizations to keep up with the competition.
The use of open source has enabled everyone to accelerate the speed of innovation, however, the process of exploring and trying open source frameworks is still fairly tedious, with much friction in the transition from the initial exploration to full production. With the new Catalog service many users and organizations can increase their speed of innovation dramatically by simplifying the process of exploring and integrating new open source frameworks.